Our previous idea about how to solve
the granularity problem raises an important question: What exactly
should nodes in this system look like? What do they represent?
{kind=link}
From what I've seen so far, it's quite
obvious that the success (or failure) of a depsgraph system lives and
dies by what we choose to represent with the nodes in the graph.
With the wrong types of nodes, you're going to end up with heaps of
problems in the resulting system. For example, you may not have
enough detail to solve the certain problems (i.e. a lack of
granularity results in unresolvable phantom cycles), or you may have
too much fine grained data that you can't figure out where to start
from (and find that system performance overall crawls along).
“Data” vs “Operations”
In Brecht's notes about various
depsgraph design ideas
(http://wiki.blender.org/index.php/User:Brecht/Depsgraph),
he mentions that there are two basic types of nodes we can have in
such graphs: Data Nodes and Operation Nodes.
Here's my current understanding of what
these are:
- Data Nodes – These are essentially what we have in Blender now. The implication of these is that in the graph, we represent that blobs of data that need to be evaluated, and the relationships/links between these define the order in which we go about evaluating these chunks. We can shrink down these blobs into smaller chunks, but still, when each node is visited, we are still evaluating the data on it.
- Operation Nodes – These are things like node trees for compositing, constraints, and modifiers. They are different from Data Nodes in the sense that, instead of representing the data that gets evaluated, they represent the set of operations which operate on streams of data which pass through each node. For example, with constraint evaluation, we create a temporary datatype (“bConstraintEvalOb”) which holds the 4x4 matrix that each constraint operates on – thus, bConstraintEvalOb here acts as the piece of data that “flows” between the nodes (constraints). The key point here is that we need to have clear inputs and outputs defined for each operation, instead of each operation just dumping the results back into the ether. It seems that many other systems these days have gone down this route instead.
Which Approach to Use?
After I first saw this, my initial
reaction from reading it was something like: “Great. So, data nodes
are essentially what we have now, likely complete with all the warts
with this approach that we've seen so far. But, if they only
represent data and not operations on data, then we're somewhat
screwed with regards to trying to break up drivers and constraint
stacks and making it possible to interleave them with other
dependencies, since evaluating those effectively performs an
operation of sorts. And, we can throw the ideas of node-based
materials/constraints/yada yada out the window with it too!”.
Basically, I had serious doubts whether we could achieve all of our
goals (while leaving the door open for future extensions/cool stuff
coming in) if we kept this as a purely “data” orientated view of
the world.
However, upon re-reading this while
writing up this post, I realised that perhaps the more important
point here isn't whether we can represent operation-like nodes that
we may get if/when splitting up existing data nodes to be more
granular, but rather the problem of managing what actually happens
with regards to memory management. The data based model is pretty
clear about this (i.e. you can fetch the relevant data off the nodes
in question once they've been evaluated; and evaluating them is
simply a matter of going to a node, evaluating it, and then it is
done), though it's not that clear how that'd work out in the end for
data nodes which end up getting split into heaps of tiny little
pieces (perhaps you could make a point of only fetching from the
endpoint ones). The operation model however is murkier, as you have
datastreams which mysteriously get created/merged/duplicated/etc.
That's perhaps why we have things like Input/Result nodes in the Node
Editor as clearly defined endpoints for these results. Another
potential problem with such datastreams getting created/deleted all
over in the background is that we could be in for a hell of a lot
more weird and fiendishly hard to debug errors (much like the
threading problems which we're now plagued with in the
rendering/compositing areas).
Locality/Isolatability + Duplis
Then again, if we aim to do something
about the Locality/Isolatability goals, then we're really going to
have to be making multiple copies of data anyway. It's practically
required as a matter of good threading hygine to do it, but also
since with the way we've got things now, it's simply impossible to
locally override settings for particular instances without causing
all instances to end up only looking like the way that the last guy
who touched that data left it. As a side effect of that, we'll need
to be finding a way of extracting out or managing the data for those
copies, which isn't really possible representing “data elements”
which need evaluation. For instance, consider things like duplis
and/or particles using those duplis: do we seriously want nodes
representing each of these instances in the graph, even if they may
only end up getting created part-way through the scene being
evaluated?
Physics Sims
There is also the question of what to
do about physics sims: do they realistically represent “data”, or
are they purely “operations”? In the case of sims such as fluids,
cloth, softbody, and smoke, it could be argued that since they're
done as modifiers, that puts them in the category of “operations”
(given our prior classification of these, and the fact that they have
well defined inputs/outputs working on a datastream - “DerivedMesh”
data).
Let's also consider rigidbody sims
though. These operate on object level. While the actual mechanics of
the simulation process are done inside a bit of a “blackbox”,
what happens is that we are effectively evaluating the “RigidBodyOb
data” on the objects when we do this. Furthermore, even if we split
the evaluation step into two separate simulation runs or groups (as
would be needed if we were to support the ability to parent objects
to simulation objects, and then perhaps eventually have some of the
children of those be part of a second simulation), then those
“groups” themselves could perhaps be considered instances of
“data” (in this case, several other “RigidBodyOb data”
blocks that need evaluating).
RNA Updates and Other Use Cases
We also must not forget the problems we
had earlier with RNA Update callbacks. As it stands, when some
properties are updated, we must wait to perform a proper flushing
step on the block level (instead of in the property set/change
callbacks, where we only know about a single property and/or the
local struct that this may reside in, which in some cases turns out
to be far too restrictive, as sometimes the computations needed in
response to property changes need to go up a few levels to access
data stored elsewhere). Examples of this include the
Mapping/Transform nodes, which currently cannot be animated/driven
because we have no way of getting those property update callbacks –
which are used to force the transform values set via the properties
into the underlying matrix used to actually apply the node's effects
– to run, without also inadvertantly causing some of the other RNA
callbacks to start tagging other nodes for updates, thus triggering
infinite loops in some setups.
Clearly it would be nice to find a way
to handle these within the depsgraph structure, but once again, are
they more “data” or “operation”?
- As Data – we can create some nodes to represent the underlying data which needs to be updated/evaluated (say, the mapping node's matrix) which will then get queued for evaluation if the property-data chunk of the datablocks (also represented as another node) changes, and thus triggers a re-evaluation of it and its children.
- As Operation – we simply take such update callbacks (which perform legitimate flushing operations) as “operation nodes”, whose job is to act on the data once changes happen. However, on second thought, the difference here is probably only really semantic, OR doesn't even exist in any way... Hrm... maybe this could work as “data” (if we stick to “data” = “evaluate stuff attached to a blob of memory”, vs “operation” = “take streams of inputs, defrobulate, spit out outputs streams”).
Hybrids?
All along, we've been assuming that
these two types of graph design are mutually exclusive. Must it be
that way? Can't we have a strong data-core (mainly tailored towards
the simple cases with no multi-users/overlaps/tight-coupling), with
operation nodes interleaved between these to smooth over some of the
trickier aspects which need to take place split up? Or is this all
just incoherrent babbling at the end of a long day of thinking and
coding after getting a rude awakening in the morning when a bunch of
arborists showed up to noisly cut down and mulch a tree that used to
stand across the road?
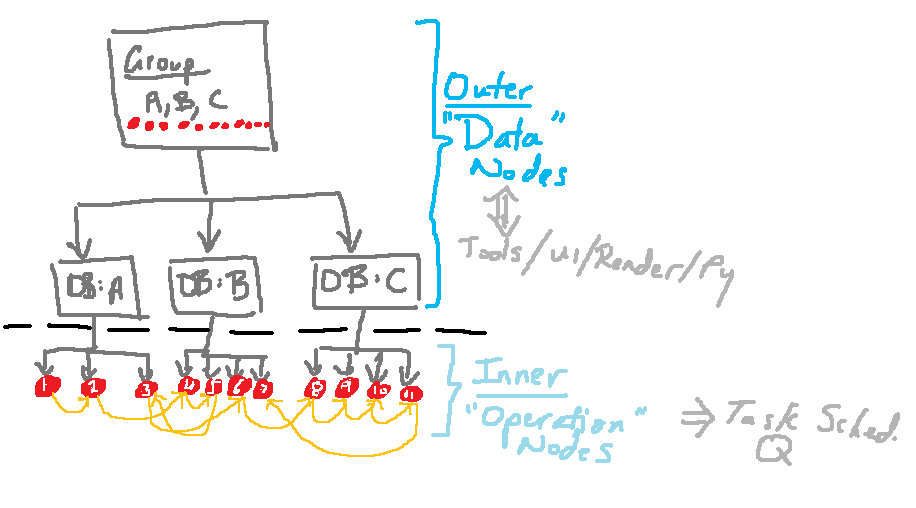
A Hierarchical Composition/Split
Model
Perhaps there's a way of having a bit
of a split model combining both, using them where appropriate.
On an “outer” level, we have a
bunch of predominantly “data”-orientated nodes, whose main
purpose is make it easy to find/filter/flag nodes in the graph with
changes. These would correspond to actual entities that the rest of
Blender deals in (i.e. ID Blocks, RNA Structs/Properties, etc), so
broad level changes can get easily filtered down to these. As such,
they could also help to define the memory stores for where results
ultimately end up, making it easy to fetch the results, and allowing
us to pass these downwards to the actual operation snippets.
On an “inner” level, for each
datablock, we have a bunch of “atomic operations” as detailed in
"The
Granularity Problem". These are basically “operation”
nodes which perform the actual tasks of performing evaluation steps
onto the given contexts (i.e. well defined inputs and outputs from
the tightly boxed operations). Ultimately, although these operation
nodes are housed within the toplevel groups, and the specific sets of
steps/operations present are generated by the datablocks tier, at
low-level, these operation nodes are still free to be able to be
queued up and linked together to form a dense, interleaved network –
that is, within a group, they are free to perform the types of things
we described earlier when talking about granularity.
The following diagram tries to summarise the setup mentioned here:

{kind=link}
At this stage, this is still just quite a rough concept, but so far, it looks like the right way to go...
No comments:
Post a Comment